Convolutional Neural Networks for Sentence Classification
12 Jun 2017 | PR12, Paper, Machine Learning, CNN, NLP이번 논문은 2014년 EMNLP에 발표된 “Convolutional Neural Networks for Sentence Classification”입니다.
이 논문은 문장 수준의 classification 문제에 word vector와 CNN을 도입한 연구를 다루고 있습니다.
Introduction
이 논문을 이해하기 위해서는 Word Embedding과 Word2vec에 대한 사전 지식이 필요합니다.
Word Embedding
Word embedding은 NLP (Natural Language Processing, 자연어 처리) 분야에서 컴퓨터가 인식할 수 있도록 수치적인 방법으로 단어를 표현하는 방법입니다. 초기의 NLP는 one-hot encoding을 많이 사용했는데, 간단하고 적용하기 쉬웠지만 단어들 간의 관계를 표현할 수 없는 한계가 있었습니다.
Word2vec
단어 자체의 의미를 multi-dimensional vector로 표시하기 위한 연구는 1980년대부터 있었다고 합니다. 하지만 2000년대 들어 NNLM (Neural Network based Language Model)과 RNNLM (Recurrent NNLM)을 거쳐 2013년 Google이 발표한 Word2vec이 현재 가장 state-of-the-art 기술로 각광받고 있습니다. Word2vec의 학습 결과를 시각화해보면 아래 그림처럼 벡터들의 방향과 단어들의 의미가 연관성이 있는 것을 확인할 수 있습니다.
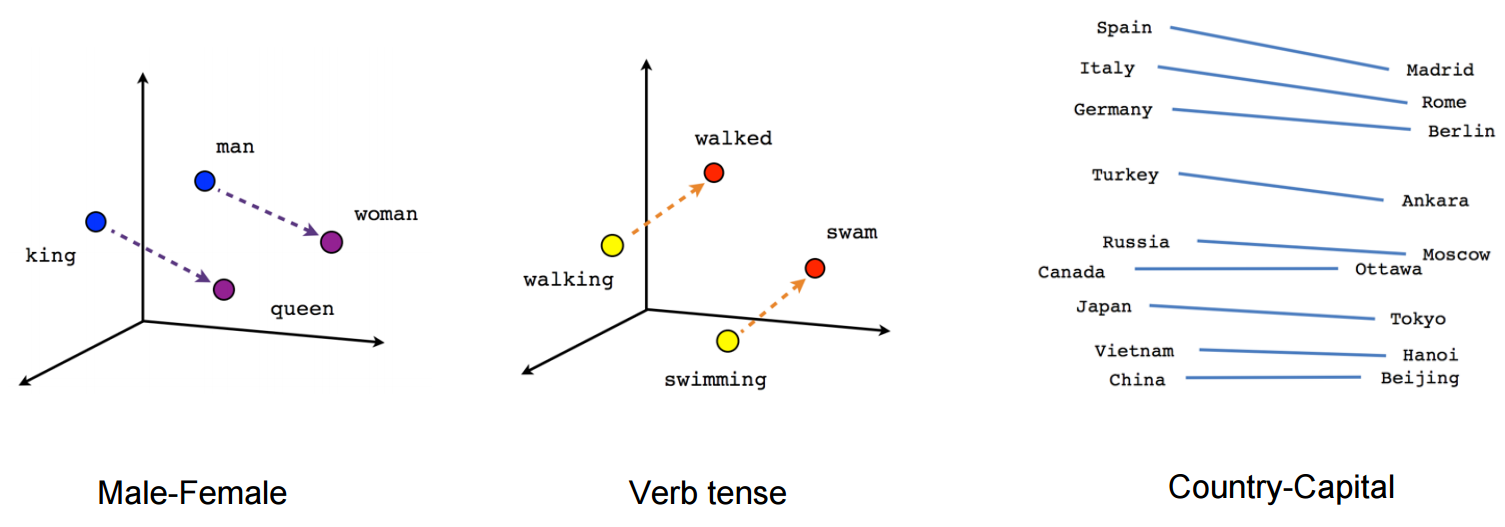 (그림 출처: TensorFlow의 word2vec tutorial)
(그림 출처: TensorFlow의 word2vec tutorial)
Model
이 논문에서 사용한 아키텍처 모델은 Collobert의 JLMR 2011 논문 “Natural Language Processing (almost) from Scratch”에서 사용한 CNN 모델에 기반한 구조입니다 (아래 그림).
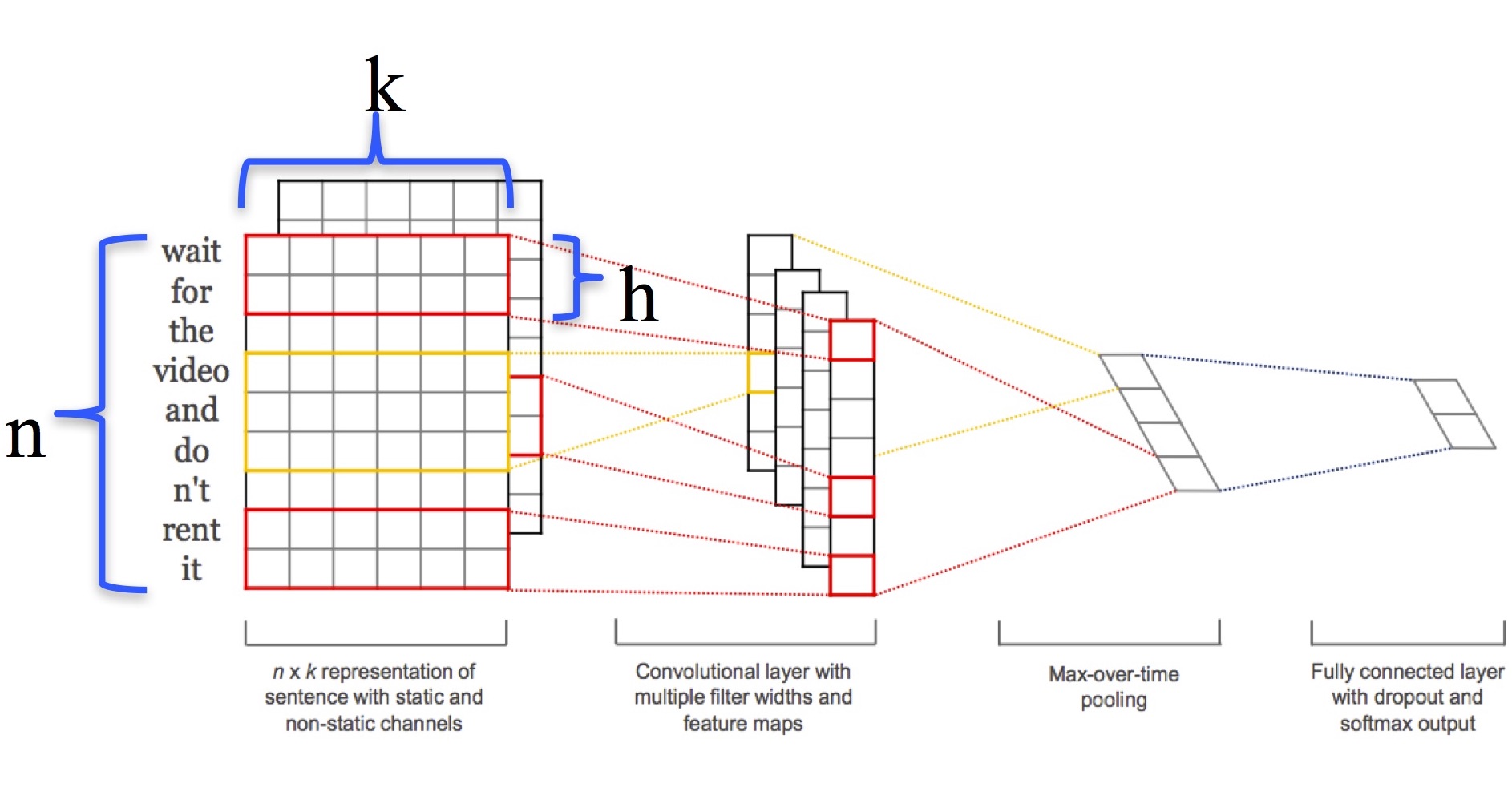
이 그림에서 $n$은 문장에 나오는 단어의 개수, $k$는 word vector의 dimension, $h$는 filter window size를 의미합니다. 길이 $n$의 문장은 word vector 를 연결해 아래 (1)식과 같이 표현됩니다.
이 때, $\oplus$는 concatenation 연산자를 의미합니다. Convolution 연산은 윈도우 크기 $h$ 단위로 이뤄지며, filter의 weight $\mathbf{w}$에 대해 feature $c_i$는 아래 식과 같이 계산됩니다.
위 식에서 $b$는 bias, $f$는 non-linear (ReLU) 함수입니다. 모든 word window 에 필터를 적용해 아래 (3)식과 같이 feature map을 계산합니다.
여기에 max-pooling 연산을 거쳐 얻은 최대 값을 fully-connected layer에 집어 넣습니다. Fully-connected layer에는 dropout을 적용하고 마지막 단에서 softmax 출력을 얻습니다.
이 논문의 실험에서는 static과 non-static 두 가지 채널을 구분하고 있습니다. Word vector가 training 중에 변하지 않는 것이 static 채널이고, word vector를 backpropagation을 통해 fine-tune하는 것이 non-static 채널입니다.
Dataset과 실험 환경
실험에서 사용한 hyper-parameter들과 training 조건은 아래와 같습니다.
- convolution layer: 1 layer with ReLU
- filter window size ($h$): 3, 4, 5 with 100 feature maps each (total 300)
- regularization: dropout (rate 0.5), $L_2$ norm constraint
- mini batch size: 50
- SGD with Adadelta
실험에는 word2vec의 pre-trained embedding을 가져와 사용했습니다. word2vec은 Google News의 1000억 개 단어로 훈련된 vector입니다.
또한, 실험에서는 4가지의 변형된 CNN 모델을 사용했습니다.
- CNN-rand: word2vec을 사용하지 않고 모든 단어를 random 초기화
- CNN-static: word2vec으로 pre-train, 모든 word vector를 static하게 유지.
- CNN-non-static: word2vec으로 pre-train, word vector를 학습하며 fine-tune.
- CNN-multichannel: static 채널과 non-static 채널 모두 사용
실험 결과
아래 그림은 실험 결과를 요약한 테이블입니다.
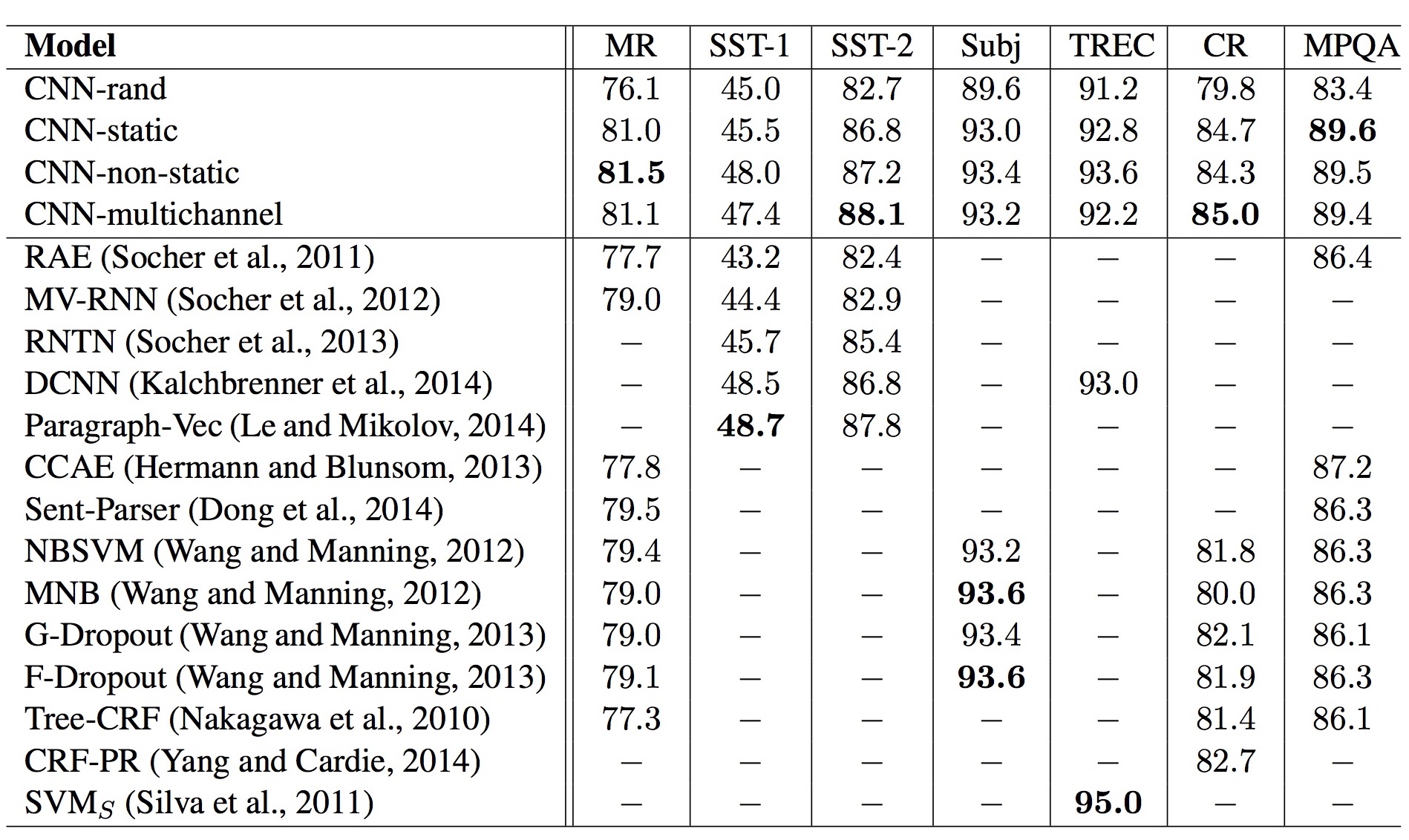
간단히 정리하면 다음과 같습니다.
- CNN-rand: word2vec 없이는 성능이 그다지 좋지 않다.
- CNN-static: word2vec 덕분에 성능이 많이 개선되었다.
- CNN-non-static: fine-tuning이 도움이 되기는 하지만 큰 개선은 아니다.
- CNN-multichannel: static 채널과 non-static 채널 모두 사용해도 큰 차이는 없다.
이 밖에, 실험 결과에서 다음과 같은 관찰을 할 수 있었습니다.
- Dropout이 regularizer로써 잘 동작하며 2~4%의 개선 효과가 있었다.
word2vec에 없는 단어의 경우 초기화가 중요하다: variance를 pre-trained와 동일하게 하면 성능 향상- 어떤 word vector를 사용하는 지도 중요하다: word2vec이 다른 word vector보다 훨씬 성능이 뛰어났다.
- Adadelta는 Adagrad와 비슷한 결과를 내지만 더 적은 수의 epoch로 충분했다.
비록 실험 모델이 단순하고 결과에 대한 깊은 분석이 부족한 감이 있지만, 이 논문은 NLP에 CNN을 적용했을 때 모델이 단순하더라도 word2vec으로 pre-training하면 높은 성능을 낼 수 있음을 보였다는 점에서 의미가 있다고 하겠습니다.
– Jamie;
References
- Yoon Kim의 논문 “Convolutional Neural Networks for Sentence Classification”
- Yoon Kim의 슬라이드 “Convolutional Neural Networks for Sentence Classification”
- Yoon Kim의 GitHub “Convolutional Neural Networks for Sentence Classification”
- Google의 word2vec 공식 페이지
- TensorFlow의 word2vec tutorial
- 곽근봉 님의 슬라이드 “Convolutional Neural Networks for Sentence Classification”
- Wikipedia의 Word embedding
- Wikipedia의 Word2vec
- Tomas Mikolov의 논문 (word2vec) “Distributed Representations of Words and Phrases and their Compositionality”
- 김범수 님의 블로그 “word2vec 관련 이론 정리”
- R. Collobert의 논문 “Natural Language Processing (almost) from Scratch”
- Wikipedia의 Dropout
- Adadelta 논문 “ADADELTA: An Adaptive Learning Rate Method”